SQL 执行顺序
from子句组装来自不同数据源的数据where子句基于指定的条件对记录行进行筛选group by子句将数据划分为多个分组- 使用聚集函数进行计算
- 使用
having子句筛选分组 - 计算所有的表达式
select的字段- 使用
order by对结果集进行排序 limit
限制返回行数(limit)
使用 limit限制最后返回数据的条数。
select
device_id
from
user_profile
limit
2;空值相关
空值判断
空值只能用 is和 is not判断。
select
device_id,
gender,
age,
university
from
user_profile
where
age is not null;coalesce
coalesce(expression_1, expression_2, ..., expression_n)依次参考各参数表达式,遇到非 null 值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。
最常见的应用是coalesce(success_cnt, 0),这样使 null 值返回 0,例如 count 或者 avg 时可以连 null 值也统计。
分组(group by)
group by后面可以跟多个字段就是根据多个字段进行分组
合并(union)
合并两个或多个select语句的结果。
默认地,union操作符选取不同的值。
如果允许重复的值,请使用union all。
条件函数
case
CASE 测试表达式
WHEN 简单表达式1 THEN 结果表达式1
WHEN 简单表达式2 THEN 结果表达式2 …
WHEN 简单表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END从上到下将测试表达式的值与每个when子句的简单表达式进行比较。
如果某个简单表达式的值与测试表达式的值相等,则返回第一个与之匹配的when子句所对应的结果表达式的值。
如果所有简单表达式的值与测试表达式的值都不相等,若指定了else子句,则返回else子句中指定的结果表达式的值;若没有指定else子句,则返回 null。
例题
统计每个班男生和女生的数量各是多少,统计结果的表头为,班号,男生数量,女生数量。
SELECT 班号,
COUNT(CASE WHEN 性别=‘男’ THEN ‘男’ END) 男生数,
COUNT(CASE WHEN 性别=‘女’ THEN ‘女’ END) 女生数
FROM 学生表 GROUP BY 班号没有匹配上时返回 null,而 count(null) = 0,所以不会被计算上。
if
if(条件表达式,值1,值2)如果条件表达式为 true,返回值1,为 false,返回值2。
分类大于二时一般选择case。
带条件的计数
sum(if (条件, 1, 0))
if函数也可以换成CASE WHEN 条件 THEN 1 END
例题
获取复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,对于在8月份没有练习过的用户,答题数结果返回0。
用户信息表 user_profile
| id | device_id | gender | age | university | gpa |
|---|
题目练习记录表 question_practice_detail
| id | device_id | question_id | result | date |
|---|
select
u.device_id,
'复旦大学' as university,
count(question_id) as question_cnt,
sum(if (q.result = 'right', 1, 0)) as right_question_cnt
from
user_profile as u
left join question_practice_detail as q on u.device_id = q.device_id
and month (date) = '08'
where
u.university = '复旦大学'
group by
u.device_id日期函数
日期格式化函数
day/month/year
select day(createtime) from life_unite_product --取时间字段的天值
select month(createtime) from life_unite_product --取时间字段的月值
select year(createtime) from life_unite_product --取时间字段的年值date_format
date_format(date, format)参数:
date:参数是合法的日期。format:规定日期/时间的输出格式。是个字符串,使用下表中的格式组合。例如 "%Y-%m-%d" 显示为 "2023-03-07"
| 常用格式 | 描述 |
|---|---|
| %y | 年,2 位 |
| %Y | 年,4 位 |
| %m | 月,数值(00-12) |
| %d | 月的天,数值(00-31) |
| %j | 年的天 (001-366) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %H | 小时 (00-23) |
| %i | 分钟,数值(00-59) |
| %w | 周的天 (0=星期日, 6=星期六) |
时间差函数
timestampdiff
timestampdiff(interval, datetime1,datetime2)返回(datetime2-datetime1)的时间差,结果单位由interval参数给出。
interval参数:
- frac_second 毫秒(低版本不支持,用second,再除于1000)
- second 秒
- minute 分钟
- hour 小时
- day 天
- week 周
- month 月
- quarter 季度
- year 年
datediff
传入两个日期参数,比较DAY天数,第一个参数减去第二个参数的天数值。
timediff
返回两个时间相减得到的差值,第一个参数减去第二个参数的时间值。
SELECT timediff('2018-05-21 14:51:43','2018-05-19 12:54:43'); -- 结果:49:57:00字符串操作
字符串匹配
列名 [NOT] LIKE
匹配串中可包含如下四种通配符:
_:匹配任意一个字符%:匹配0个或多个字符[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达)[^ ]:不匹配[ ]中的任意一个字符
/*查询学生表中姓‘张’的学生的详细信息*/
SELECT * FROM 学生表 WHERE 姓名 LIKE '张%'
/*查询姓“张”且名字是3个字的学生姓名*/
SELECT * FROM 学生表 WHERE 姓名 LIKE '张__'
/*如果把姓名列的类型改为char(20),在SQL Server 2012中执行没有结果。原因是姓名列的类型是char(20),当姓名少于20个汉字时,系统在存储这些数据时自动在后边补空格,空格作为一个字符,也参加LIKE的比较。可以用rtrim()去掉右空格*/
SELECT * FROM 学生表 WHERE rtrim(姓名) LIKE '张__'
/*查询学生表中姓‘张’、姓‘李’和姓‘刘’的学生的情况*/
SELECT * FROM 学生表 WHERE 姓名 LIKE '[张李刘]%'
/*查询学生表表中名字的第2个字为“小”或“大”的学生的姓名和学号*/
SELECT 姓名,学号 FROM 学生表 WHERE 姓名 LIKE '_[小大]%'
/*查询学生表中所有不姓“刘”的学生*/
SELECT 姓名 FROM 学生 WHERE 姓名 NOT LIKE '刘%'
/*从学生表表中查询学号的最后一位不是2、3、5的学生信息*/
SELECT * FROM 学生表 WHERE 学号 LIKE '%[^235]'字符串截取
substring/substr/mid
substring(string, start, length)string:要处理的字符串start:分隔符length:计数
从位置 start 开始提取 length 个字符,start 为负数则从末尾数。
需要注意 SQL 中第一位 index 为 1 而不是 0。
substring_index
substring_index(string, delimiter, number)string:要处理的字符串delimiter:分隔符number:计数
如果number是正数,那么就是从左往右数,第 N 个分隔符的左边的全部内容。
如果number是负数,那么就是从右边开始数,第 N 个分隔符右边的所有内容。
-- str=www.wikidm.cn
substring_index(str,'.',1) -- www
substring_index(str,'.',-1) -- cn
substring_index(substring_index(str,'.',-2),'.',1) -- 两个 substring_index 得到中间的 wikidm字符串拼接
concat
连接参数中的所有字符串。
如有任何一个参数为 null,则返回值为 null。
concat(str1,str2,…)concat_ws
意思是 concat with separator
concat_ws(separator,str1,str2,…)参数:
separator:其它参数的分隔符。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。str1, str2, ...:要连接的各个字符串。函数会忽略任何分隔符参数后的 NULL 值,但是不会忽略任何空字符串。
group_concat
group_concat([distinct] str1 order by 排序字段 asc/desc separator '分隔符')参数:
distinct:可选关键字,一组内的结果没有重复元素。str1:要连接的字符串。order by 排序字段 asc/desc:可选关键字,对要连接的字符串排序。separator '分隔符':一个组内以什么样的分割符进行连接,默认的情况下是以逗号的形式连接。
字符串大写
upper(str)窗口函数
分组的基础上排名或者聚合
窗口函数原则上只能写在 select 子句中
基本语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)<窗口函数>的位置,可以放以下两种函数:
- 专用窗口函数,比如
rank,dense_rank,row_number等。 - 聚合函数,如
sum,avg,count,max,min等。
专用窗口函数
先分组,然后每个组里各自排序
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表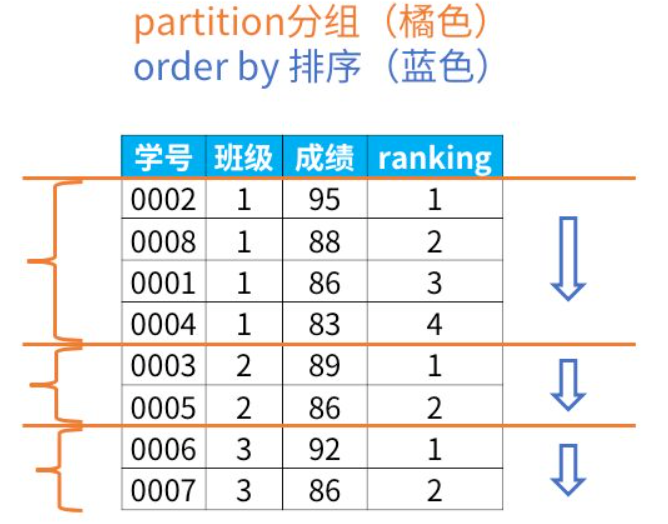
三个函数的区别
rank函数:如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是: 1,1,1 ,4。dense_rank函数:如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是: 1,1,1 ,2。row_number函数:不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的 1,2,3 ,4。
例题
取出每个学校的最低 gpa。
字段:
| id | device_id | gender | age | university | gpa |
|---|
select
device_id,
university,
gpa
from
(
select
device_id,
university,
gpa,
rank() over (
partition by
university
order by
gpa
) as rk
from
user_profile
) as a
where
a.rk = 1聚合函数
一些需要注意的点
- 从开头 SQL 执行的顺序可以看出
where和having都在select之前,所以where和having中不能使用select中定义的别名,但是仅在 MYSQL 中,默认有对 SQL 语法的扩展,此时having中能使用select中定义的别名。 order by和group by一起使用时,order by要放在group by的后面,order by的列,必须是出现在group by子句里的列。前者可以用 SQL 执行顺序解释,后者因为order by对结果集进行排序,非group by子句中的列并不在结果集中。- MYSQL 从 SQL 执行顺序中
group by开始可以使用select中的别名,和 MYSQL 默认开启的 only_full_group_by 模式有关,也就是第一条中说的对 SQL 语法的扩展。
